
The enterprise AI landscape has evolved rapidly over the last two years. Organizations are no longer experimenting with AI – they are integrating it into customer support, internal operations, software development, data analysis, and decision-making processes.
However, deploying a generic LLM often leads to a common challenge: the model lacks organization-specific knowledge and struggles to deliver consistent, business-aligned outputs.
This is where two popular approaches enter the conversation:
- Retrieval-Augmented Generation (RAG)
- Fine-Tuning
Although many teams view them as competing strategies, the reality is more nuanced. RAG and Fine-Tuning address different challenges, and selecting the wrong approach can lead to unnecessary costs, performance issues, and maintenance overhead. Industry experts increasingly recommend evaluating whether your challenge is a knowledge problem or a behavior problem before making the decision.
Let’s explore both approaches in depth.
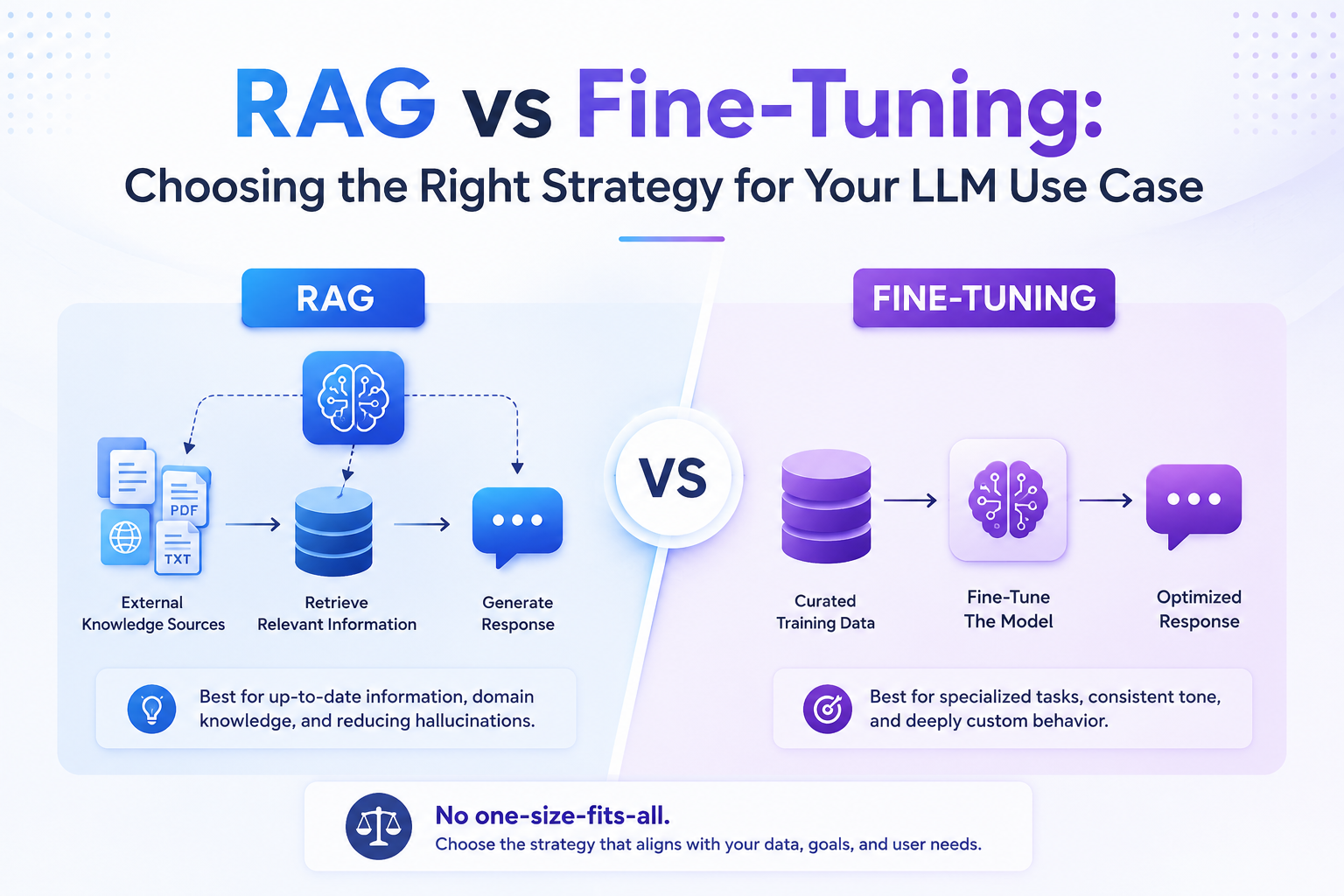
Understanding RAG (Retrieval-Augmented Generation)
RAG is an AI architecture that enables an LLM to access external knowledge sources in real time.
Instead of relying solely on information learned during training, the model retrieves relevant documents, records, or data points from a knowledge base before generating a response.
How RAG Works
A typical RAG workflow includes:
- User submits a query.
- The system searches a vector database or knowledge repository.
- Relevant documents are retrieved.
- Retrieved information is added to the model’s context.
- The LLM generates a response grounded in the retrieved data.
This approach effectively gives the model access to the latest company knowledge without retraining the model itself.
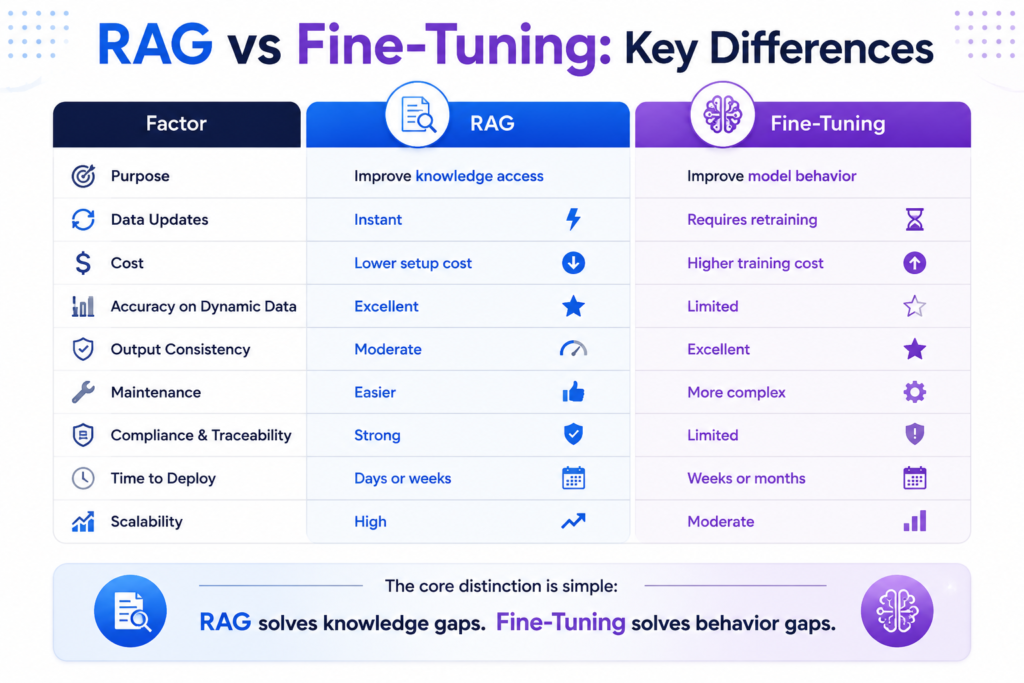
Benefits of RAG
Real-Time Knowledge Access
Business data changes constantly. Policies, product documentation, pricing structures, and compliance requirements evolve over time.
With RAG, updating information is as simple as updating the knowledge base.
Reduced Hallucinations
Because responses are grounded in retrieved content, RAG significantly improves factual accuracy and traceability.
Lower Operational Cost
There is no need to retrain the model whenever information changes.
Better Compliance
Organizations can provide citations and references for generated responses, making auditing easier.
Common Use Cases
- Enterprise knowledge assistants
- Customer support chatbots
- Legal document search
- Internal HR portals
- Product documentation systems
- Compliance and policy management
For most knowledge-driven enterprise applications, RAG is often the preferred starting point due to its flexibility and maintainability.
Understanding Fine-Tuning
Fine-Tuning modifies the model itself.
Instead of retrieving external information, developers train the model on custom datasets to alter its behavior, communication style, reasoning patterns, or domain expertise.
The model essentially learns from examples and incorporates those patterns into its parameters.
How Fine-Tuning Works
The process generally includes:
- Collecting high-quality training examples.
- Preparing labeled datasets.
- Training the model on domain-specific data.
- Validating performance improvements.
- Deploying the customized model.
Unlike RAG, knowledge becomes embedded within the model.
Benefits of Fine-Tuning
Consistent Output Formatting
Fine-Tuned models excel when responses must follow specific templates or structures.
Domain-Specific Expertise
Industries such as healthcare, finance, and legal services often require specialized terminology and workflows.
Improved Brand Voice
Organizations can train models to align with their communication standards.
Reduced Prompt Complexity
A Fine-Tuned model often requires fewer instructions to achieve the desired output.
Common Use Cases
- Brand-specific content generation
- Code generation assistants
- Document classification
- Intent detection systems
- Structured data extraction
- Industry-specific workflows
Fine-Tuning becomes particularly valuable when the goal is to improve how the model behaves rather than what information it knows.
When Should You Choose RAG?
Choose RAG if:
Your Information Changes Frequently
If you’re working with documents, policies, inventories, or customer records that evolve regularly, RAG provides unmatched flexibility.
You Need Explainability
Industries like healthcare, finance, and legal services often require transparent sources behind generated responses.
You Want Faster Deployment
RAG implementations can often be delivered significantly faster than Fine-Tuning projects.
Cost Efficiency Matters
Maintaining a knowledge base is generally less expensive than repeatedly retraining models.
Example
Imagine a multinational company with thousands of internal documents.
Using RAG, employees can instantly query updated policies without requiring model retraining every time a document changes.
When Should You Choose Fine-Tuning?
Choose Fine-Tuning if:
Output Format Is Critical
For example:
- JSON generation
- Structured reports
- Classification systems
- Workflow automation
You Need Specialized Behavior
Fine-Tuning helps models consistently follow organization-specific communication patterns.
You Want Better Task Performance
Certain highly specialized tasks can benefit from Fine-Tuning because the model internalizes patterns rather than repeatedly receiving instructions.
Example
A financial institution generating compliance reports may require strict formatting standards and terminology consistency that Fine-Tuning can provide.
The Rise of Hybrid Architectures
The most advanced AI systems today increasingly combine both approaches.
A hybrid architecture uses:
- Fine-Tuning to shape behavior, tone, and response structure.
- RAG to provide accurate, real-time knowledge.
This strategy offers the best of both worlds:
- Up-to-date information
- Consistent output quality
- Reduced hallucinations
- Better user experiences
Many mature enterprise AI deployments now adopt this architecture because it balances accuracy, flexibility, and scalability.
Real-World Decision Framework
Before selecting a strategy, ask these questions:
Question 1:
Does the model lack access to business information?
Yes → Use RAG
Question 2:
Does the model know the information but communicate poorly?
Yes → Use Fine-Tuning
Question 3:
Do you need both accurate information and specialized behavior?
Yes → Use Hybrid AI
A practical rule followed by many AI engineering teams is:
Start with RAG. Introduce Fine-Tuning only when evaluation metrics show that behavior, formatting, or task execution remains a challenge.
Future Outlook
As LLM technology continues to evolve, the debate is shifting away from “RAG versus Fine-Tuning” toward “How can they work together?”
Organizations are realizing that AI success depends less on model size and more on architecture design.
The companies that achieve the highest ROI from AI investments are those that build systems capable of:
- Accessing current knowledge
- Producing reliable outputs
- Scaling efficiently
- Remaining compliant and auditable
RAG and Fine-Tuning are not competitors – they are complementary tools in the modern AI engineering toolkit.
Conclusion
Choosing between RAG and Fine-Tuning is ultimately about understanding the problem you’re trying to solve.
If your challenge revolves around accessing and managing knowledge, RAG is usually the most practical and cost-effective solution.
If your goal is improving model behavior, consistency, and task performance, Fine-Tuning can deliver substantial benefits.
For most enterprise AI initiatives, however, the strongest long-term strategy is often a hybrid approach that combines the knowledge grounding of RAG with the behavioral optimization of Fine-Tuning. By aligning your AI architecture with your business objectives, you can build intelligent systems that are not only accurate and scalable but also capable of delivering measurable business value in the years ahead.
