

In today’s digital-first economy, data is no longer a byproduct of business operations – it’s the fuel that powers innovation, customer experiences, automation, and strategic decision-making.
The challenge? Data is being generated at an unprecedented scale.
Every website click, mobile app interaction, payment transaction, API request, IoT sensor reading, and customer activity creates a continuous stream of information. Traditional batch processing systems, which move data every few hours or once a day, often struggle to keep pace with modern business demands.
Organizations now require near real-time visibility into their operations. They want instant insights, live dashboards, proactive alerts, personalized customer experiences, and AI systems that react to events as they happen.
This is where real-time data pipelines become a competitive advantage.
By combining Apache Kafka for event streaming and dbt (Data Build Tool) for data transformation, businesses can create scalable, reliable, and analytics-ready architectures that bridge operational systems with actionable insights. Kafka serves as the backbone for streaming and distributing data, while dbt transforms raw data into trusted business models for reporting and analytics.
Why Real-Time Data Matters
Imagine running an eCommerce platform.
When a customer places an order, multiple actions should happen instantly:
- Inventory should update automatically.
- Payment verification should be processed.
- Customer notifications should be triggered.
- Fraud detection systems should analyze the transaction.
- Business dashboards should reflect the sales immediately.
If these processes depend on nightly batch jobs, opportunities are missed, and customer experiences suffer.
Modern enterprises increasingly rely on real-time data for:
- Personalized customer experiences
- Operational monitoring
- Fraud detection
- Supply chain optimization
- Predictive maintenance
- AI-powered recommendations
- Live business intelligence
Organizations that can act on fresh data often outperform competitors who rely on delayed insights.
Understanding the Modern Data Pipeline Stack
A modern real-time pipeline typically consists of four layers:
1. Data Producers
These are systems generating events:
- Web applications
- Mobile apps
- Databases
- Microservices
- IoT devices
- SaaS platforms
Every significant business action creates an event that can be captured and streamed.
2. Streaming Layer (Apache Kafka)
Kafka acts as the central nervous system of the architecture.
Instead of applications communicating directly with one another, they publish events to Kafka topics. Multiple consumers can then independently subscribe and process those events.
Benefits include:
- High throughput
- Fault tolerance
- Scalability
- Event replay capabilities
- Decoupled architecture
This flexibility allows engineering teams to evolve systems without creating tightly coupled dependencies.
3. Processing & Transformation Layer
Before data becomes useful, it often requires:
- Validation
- Cleansing
- Enrichment
- Aggregation
- Standardization
Streaming tools and transformation frameworks help convert raw events into meaningful business information.
4. Analytics & Consumption Layer
Finally, transformed data is delivered to:
- Data warehouses
- BI dashboards
- AI models
- Reporting systems
- Customer-facing applications
This is where business value is realized.
Where Apache Kafka Fits In
Apache Kafka has become the industry standard for event-driven architectures because it solves one critical problem exceptionally well: moving data reliably and at scale.
Think of Kafka as a high-speed data highway.
Instead of applications constantly polling databases or exchanging information through complex integrations, events are published once and consumed by many systems simultaneously.
Key Kafka Components
Producers
Applications that publish events to Kafka.
Examples:
- Checkout service
- CRM system
- Mobile application
- IoT device
Topics
Logical channels where events are stored.
Examples:
- orders
- payments
- customer_activity
- inventory_updates
Consumers
Applications that subscribe to topics and process events.
Examples:
- Analytics systems
- Fraud detection services
- Notification engines
Kafka Connect
A framework that simplifies moving data between Kafka and external systems without custom coding.
Where dbt Fits In
While Kafka excels at moving data, organizations still need a reliable way to transform that data into trusted business metrics.
This is where dbt shines.
dbt enables data teams to define transformations using SQL while introducing software engineering best practices, such as:
- Version control
- Testing
- Documentation
- CI/CD workflows
- Data lineage tracking
Rather than manually creating complex SQL scripts, teams can build reusable transformation models that are easier to maintain and scale.
With dbt, raw event data can become:
- Revenue reports
- Customer lifetime value metrics
- Product performance dashboards
- Marketing attribution models
- Executive KPI reports
The result is cleaner, more reliable analytics across the organization.
A Practical Kafka + dbt Architecture
A production-ready architecture often follows this pattern:
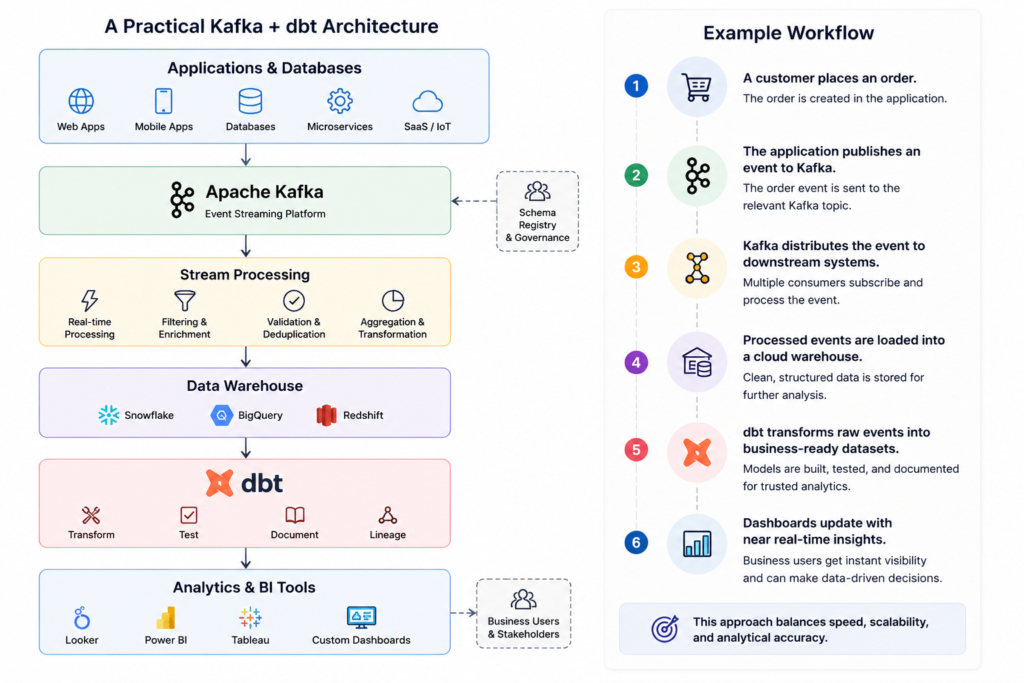
Best Practices for Building Real-Time Pipelines
Design Event-Driven Architectures
Avoid tightly coupled integrations.
Publishing events allows systems to evolve independently and reduces maintenance overhead.
Implement Schema Governance
One of the most common pipeline failures occurs when data formats change unexpectedly.
Define and enforce schemas to maintain consistency across producers and consumers.
Monitor Everything
Real-time systems require visibility into:
- Consumer lag
- Throughput
- Error rates
- Data quality
- Infrastructure health
Without monitoring, small issues can quickly become major outages.
Focus on Data Quality
Fast data is valuable only when it is accurate.
Use validation, testing, and observability frameworks to ensure trust in analytics.
Plan for Scalability
As event volumes grow, your architecture should scale horizontally without major redesigns.
Kafka’s partition-based architecture makes this achievable when designed correctly.
Common Challenges Teams Face
Even the best architectures come with challenges.
Data Duplication
Real-time systems often process events multiple times.
Teams should design idempotent workflows that can safely handle duplicates.
Operational Complexity
Streaming architectures introduce additional infrastructure and monitoring requirements.
Balancing Real-Time and Batch
Not every workload requires millisecond-level latency.
Many organizations benefit from a hybrid approach that combines streaming and scheduled transformations.
Governance at Scale
As pipelines multiply, maintaining consistent standards becomes increasingly important.
Strong documentation, testing, and ownership models are essential.
The Future of Real-Time Data Engineering
The rise of AI, machine learning, automation, and customer personalization is accelerating demand for real-time architectures.
Organizations are moving beyond static reporting toward systems that continuously analyze and respond to events.
The future belongs to businesses that can:
- Process information instantly
- Deliver actionable insights faster
- Automate operational decisions
- Enable data-driven innovation
Apache Kafka provides the foundation for real-time event streaming, while dbt ensures that data remains trustworthy and analytics-ready.
Together, they form a powerful combination for modern enterprises looking to transform raw events into business value.
Final Thoughts
Real-time data pipelines are no longer reserved for technology giants. With mature tools like Apache Kafka and dbt, organizations of all sizes can build scalable, resilient, and insight-driven data platforms.
The key is not simply collecting more data – it’s creating systems that can move, process, and transform information quickly enough to drive meaningful action.
For businesses pursuing digital transformation, operational excellence, and AI-driven innovation, investing in modern real-time data architecture is rapidly becoming a necessity rather than a luxury.
The companies that master real-time data today will be the ones defining tomorrow’s competitive landscape.
